Free Friday #19 – Long/Short Small Caps and June Update
This Free Friday, Free Friday #19, is a user submission! It is a long/short strategy for $IWM – the Russell 2000 ETF. Both the long and the short strategy only have two rules each and only hold for 1 day. Below I’ve posted the long strategy on the left and the short strategy on the right. Short edges have certainly been difficult to find over the past few years in the US equity indexes on a daily time frame, but one hopes they’ll pay for the effort when/if things turn south!
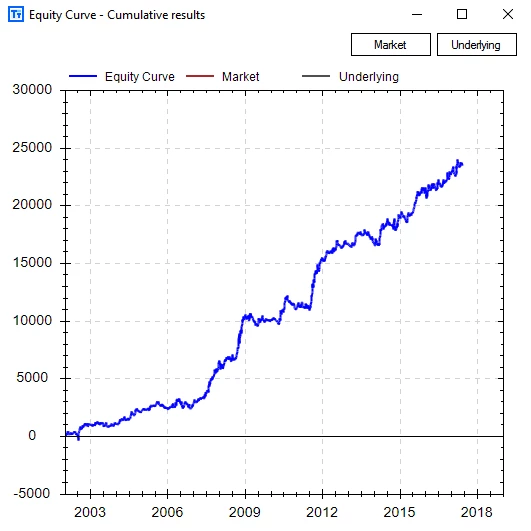
Both strategies were tested from 2002 to 2017 using 35% out of sample data. All performance is based on only a simple 100 shares per trade. *1 S&P500 futures contract is equivalent to about 500 $SPY shares for reference*
There is also $SPY (green plot) and $TLT (gold plot) plotted to see how the strategies would have performed on these markets as well; the strategy maintains profitability in both cases.
The long strategy rules are simple and all trades exit at the next day’s open.
Day number is greater than 5. Today is June 30, 2017. Today’s day number is 30.
High[3] <= Low[7]
The short strategy rules are simple as well and all trades exit at the next day’s open.
Close[3] > Low[6]
Close[0] > 8 Period Simple Moving Average
Below there is a photo of the long/short equity performance for this simple portfolio.
I also want to add an update to some of the Free Friday strategies. Things were pretty quiet for most of the futures strategies other than the equity index strategies this month.
Strategies #5, #6, #16 were the only futures strategies that traded so I wanted to show their June performance below.
Again, all are just trading 1 contract for demonstration purposes and were posted publicly months ago. You can see the strategies on twitter here: @dburgh
Thanks as always and have a Happy Fourth of July,
Dave
Thanks for reading, Dave
Free Friday #18 – Building a Strategy with Open Interest
What is Open Interest?
Open Interest is just the total number of outstanding contracts that are held by market participants at the end of each day. All derivatives have Open Interest. That is, both futures and options have their own Open Interest.
For example, the March SP500 e-mini futures contract can have its own Open Interest while the March 4000 Strike Call option can also have an its own Open Interest.
Open Interest is a proxy for cash flowing into the market. If Open Interest increases, then more money is moving into the market whereas Open Interest declining could be seen as cash leaving the market.
How is Open Interest Calculated?
Open Interest is calculated by adding all the contracts from opened trades and subtracting the contracts when a trade is closed.
For example, Steve, Chris, and Clay are trading the same futures contract. If Steve buys two contracts to open a long trade, open interest increases by two. Chris also longs four contracts, thus increasing open interest to six. If Clay puts on a short trade of three contracts, open interest again increases to a new total of nine.
Open Interest would remain at nine until any traders exit positions, which would cause a decline in open interest. If Steve sells both of his contracts and Chris exits two of his four contracts, then open interest would decrease by four from nine to five.
What is the difference between Open Interest and Volume?
Both are similar as they count total contracts traded. However, volume is a count of all traded contracts and open interest is a total of the contracts that remain open.
If a trader buys one contract, then both volume and open interest are one. If the trader sells the contract, then volume is two and open interest is zero. Volume is a running total of all transactions and Open Interest is the total of all open positions.
Is higher or lower Open Interest better?
Better is relative to your current market view or position. However, typically higher open interest is good because it signals more interest in a particular contract or strike price and may also signify that there is more available liquidity (i.e., exiting shall be easier and you may experience less slippage).
On the other hand, lower open interest may be a positive too. If the market moves or news comes out in favor of your existing position, then many traders may need to pile into your same trade pushing price in your direction.
When in doubt, test your ideas on whether higher or lower Open Interest is better. That is what Build Alpha is for! Stay tuned for an example strategy later.
What is an Open Interest strategy?
A trading strategy that relies on Open Interest as an input signal or filter can be considered an Open Interest trading strategy. For example, if Open Interest rises by x% then buy or if Open Interest is greater than the N-day average, etc.
There are a ton of creative ways to incorporate Open Interest data into your algo trading strategy development process. Creativity is often a source of alpha!
Open Interest Trading Strategy Example
As always, happy Friday!
This week I was asked by a Build Alpha user if he could build strategies using a contract’s Open Interest. Open Interest is just the total number of outstanding contracts that are held by market participants at the end of each day. So, it is intuitive that as more contracts are opened or closed then it might be telling of how traders are positioning.
This is a detailed and advanced post. Build Alpha is all point and click, but this is certainly a way more advanced blog post showing how a more sophisticated user can utilize the software.
I have to admit this is not something I have looked at previously so I was quite intrigued, but I pulled some open interest data from TradeStation and saved it.
Structing Open Interest Data
I then went on to create columns I – M below. Columns I-L are momentum measures (N period change) of Open Interest. For example, column J holds the Open Interest change over the past 5 days. Column K holds the Open Interest change over the past 10 days. Column N just holds the 3-bar sum of the 1-period momentum of Open Interest. The data can be seen below opened in Excel (I know who uses Excel anymore).
In order to use the above data in BuildAlpha, we need to format two separate files. First, we need to create a date, open, high, low, close, volume file of the actual S&P500 futures data (columns A, C, D, E, F, G). I copy and pasted those columns to a new sheet and then reformatted the date to YYYY/MM/DD, removed the headers, and saved it as a .csv file. Pictured below…
I then copy and pasted our dates and custom Open Interest data to a new excel sheet. This time instead of having the date, open, high, low, close, the volume we’ll use (copy) the date, 1-period OI change, 5-period OI change, 10-period OI change, 20-period OI change, 3 bar sum of OI as our six columns.
We can now pass this data into Build Alpha and build strategies using the Intermarket capabilities. However, in this case, our intermarket or Market 2 will be this custom open interest data and not some other asset.
Video Examples
The two videos below show exactly how I did this process in case you didn’t follow my Thursday night, two glasses of scotch deep, blog writing.
Build Alpha Open Interest Strategy Example
There is a different strategy displayed in the video above, but I promised some guys on twitterI’d share the strategy I posted Thursday. So below is the actual Free Friday #18. It holds for one day and trades when these conditions are true:
**S&P500 Futures strategy built on open interest data only and tested across Nasdaq, Dow Jones, and Russell Futures. Results just based on 1 contract**
So the last rule in Build Alpha would appear as Low2[0] > Low2[1] or translated as the low of Market 2 is greater than the low of Market 2 one bar ago. However, if you remember we created a custom data series for Market 2 and in the low column, we inserted the 10-period momentum of open interest!
Like I said this is a confusing post, but a really neat idea of how creative you can be with this software. The possibility of things we can test are immense.
Furthermore, when Build Alpha calculates RSI or Hurst, for example, using the close price of Market 2 (our intermarket selected) it will actually calculate RSI or Hurst on 20 bar momentum of the Open Interest (what we passed in for the close column)! You can also use the custom indicator/rule builder on these custom data columns.
You can also run strategies built on custom data like this through all the robustness and validation tests as well.
All in all, thanks for reading. I thought this was a cool idea taking system development to a whole new level.
In this Free Friday post, I want to pose a poll question. After reading the post and viewing the graphs please respond to the poll below and I will publish the results in another post later next week.
The question is… would you trade this strategy?
First, let’s go over the strategy. The strategy was designed using GBPAUD spot data and only has three rules to determine entry. The simulation to create this strategy (and hundreds of other strategies) took less than 2 minutes.
Vix[0] > Vix[1] – Remember [1] means 1 bar ago
High[4] <= Close[6]
Low[6] <= High[8]
The strategy has two exit criteria. A 1.5 times 20 Period ATR profit target and 1.0 times 20 period ATR stop loss.
Here are some simple performance measures
January 1, 2003 to May 1, 2017 (Last 30% Out of Sample)
Profit $147,626.20
Drawdown $8,289.70
Win Rate 54.50%
Trades 198
Sharpe 1.78
T-Test 3.76
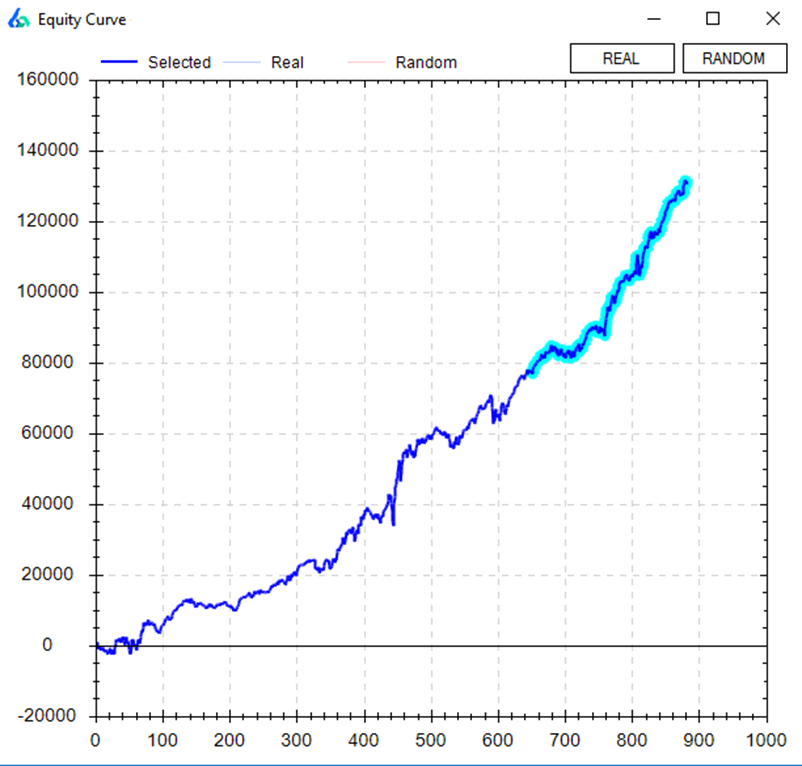
Here is the strategy’s equity curve on GBPAUD. You can see the short strategy continues to perform in the out of sample period (highlighted portion of the blue line).
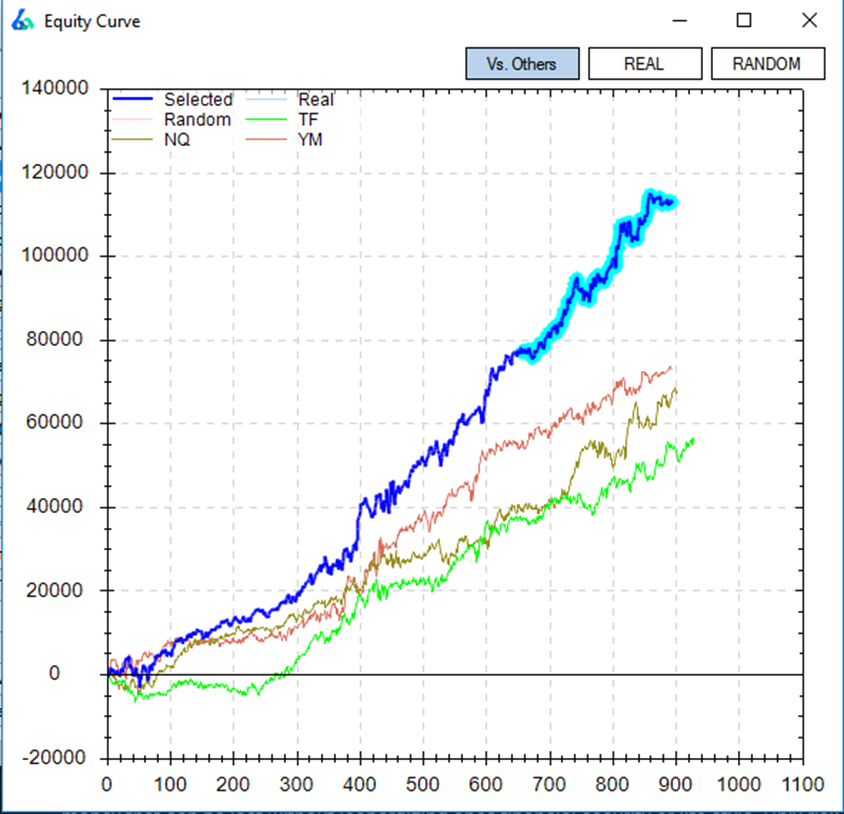
I’ve also plotted how the strategy performed on three other markets. It remains profitable on Crude Oil futures, Canadian Dollar futures, and AUDUSD spot. Generally, we like to see profitability across markets and assets. However, how good is good enough to pass the test?
Next, I want to share the randomized Monte Carlo test. This test re-trades the strategy 1000 times but randomizes the exit for each entry signal. It is a test to see if we have curve-fit our exits and if our entry is strong enough to remain profitable with random exits. We can see the randomized Monte Carlo test maintains general profitability. Some fare better and some worse.
Next I want to share the Noise Test. This test adds and subtracts random amounts of noise (percentage of ATR) to user-selected amounts of data creating 100 new price series with differing amounts of noise. The test then re-trades the strategy on these 100 new price series to see if profitability is maintained on price series with differing amounts of noise. You can see here that as we change the noise the performance degraded a bit and there are some signs of curve-fitting to the noise of the original price series.
Next, I want to share the forward simulator or variance testing results. In this test, we simulate the strategy forward but assume the winning percentage will degrade by 5% (user defined % in test settings). This is a useful test because things are never as rosey as our backtest results. Now we can get an idea of how things can play out in the future if the strategy were to win x% less than it did in our backtest. This is good for setting expectations of where we expect to be in the next N trades as well.
Risk of Ruin was set to $10,000 for this test. So interpreting these results… if the winning percentage in the future is 5% lower than our backtest than 23% of our simulations will have a drawdown of 10,000 or more.
This is all the information I want to provide for this poll. There are plenty more tests and information we can gather (like E-Ratio), but I want to avoid analysis by paralysis. Build Alpha licenses come with access to a 20+ video library where I explain what I look for in all the tests and features offered by Build Alpha.
If you answered yes to this poll and have a BA license then you can now generate trade-able code for MetaTrader4 in addition to the original TradeStation, MultiCharts, and NinjaTrader.
I also hope all you ES (S&P500) traders that email me caught the dip last Friday like the first Free Friday strategy did (pictured below). I posted this strategy on Twitter in 2016 and it only holds for 1 day. I know a few of you have adjusted the logic and I’m hoping you caught the whole move to new highs!
The role of luck in (algorithmic) trading is ever present. Trading is undoubtedly a field that experiences vast amounts of randomness compared to mathematical proofs or chess, for example.
That being said, a smart trader must be conscious of the possibility of outcomes and not just a single outcome. I spoke about this in my Chatwithtraders.com/103 interview, but I want to reiterate the point as I am often asked about it to this day.
The point I want to make is that it is very important to understand the distribution your trading strategy comes from and not just make decisions off the single backtest’s results. Doing so can increase a trader’s “luck”.
In the interview I spoke about this graph below that shows two different trading systems that have very similar backtests. The black line on the left represents system A’s backtest and the black line on the right represents system B’s backtest. For our intents and purposes let’s assume the two individual backtest results are “similar” enough producing the same P&L over the same number of trades.
The colorful lines on the left is system A simulated out (can use a variety of methods such as Monte Carlo, Bootstrapping, etc.) and the colorful lines on the right is system B simulated out using the same method. These are the possible outcomes or paths that system A and system B can take when applied to new data (Theoretically – read disclaimers about trading).
These graphs are the “distributions of outcomes” so many successful traders speak about. This picture makes it quite obvious which system you would want to trade even though system A and system B have very comparable backtests (black lines).
*There are many ways to create these “test” distributions but I will not get into specifics as BuildAlpha does quite a few of them*
Another View
This second example below demonstrates this point in another way but incorporates the role luck can have on your trading. Let’s say the blue line is the single backtest from System A (blue distribution is all possibilities). The single green line is the single backtest from System B (green possibilities).
In this graph, you can see that System A (part of the blue possibilities) was lucky and performed way better than most of the possibilities and of course better than the single backtest for System B.
You can also see that System B (part of the green possibilities) was extremely unlucky and performed way worse than most of the green possibilities.
Moving forward… do you want to count on Mother Market to give system A the same extremely favorable luck? or do you want to bet on system B’s luck evening out?
I always assume I will be close to the average/median of the distribution moving forward which would put us at the peaks of both of these possibilities or distributions… if that is the assumption then the choice is clear.
Update Announcement
Build Alpha licenses now come with an instructional video series or course that goes over all the features and how to use the statistical tests the software offers. It makes spotting systems and their related distributions much easier than Build Alpha already makes it.
Curve fitting or more commonly referred to as overfitting is creating a trading strategy that is too complex that it fails to adapt to new market data. Said another way, curve fitting is a trading strategy that shows a great backtest but fails on live data or as market behavior changes.
Curve-fitting is the fastest death for a trading or investment account once actual trading begins. Adding too many parameters and filters to improve your backtest feels good but rarely helps actual trading results in live markets.
Finding the perfect set of parameter settings to produce the perfect profit graph of past performance during strategy testing is a sure-fire way to curve fit and ultimately deplete your trading account.
Curve fitting is the black plague for system traders. The initial investment is often better donated than trading overfit strategies based on bloated hypothetical performance results.
In short, curve-fitting is finding patterns that are actually just random noise. As the curve fit trading strategy sees new data it will mistake random noise for predictive patterns causing trading losses. Preventing curve fitting and finding statistically significant patterns may be the key to your trading career.
Why do Automated Trading Strategies Fail?
Most automated trading strategies fail due to curve fitting or overoptimization. There are numerous other factors, but overfitting and overoptimization are the prime suspects.
Beginning traders hunt for the holy grail strategy and get excited over “too good to be true” backtests or hypothetical trading results. Many think a profitable backtest means a license to print money and no financial risk.
Many say, “If I could find a set of rules or parameters that does well historically on a specific trading program then I will be set to achieve profits”. Unfortunately, the markets and trading do not work this way.
Too many algo traders focus on finding the perfect trading strategy based on hypothetical performance results with the highest profit instead of finding robust strategies that can withstand losses moving forward.
Robust strategies are ones that can withstand changes in market behavior and are not sensitive to small parameter changes (i.e., possess parameter stability). Additionally, robust strategies should pass a series of robustness tests that many traders are unaware of.
Here are the 3 simplest ways to lower or avoid curve fitting risk
1. Out of Sample Testing
Out of Sample testing is simply withholding some data in your historical data set for further evaluation. For example, you have ten years of historical data and opt to put the last 30% in your back pocket.
You develop a great trading strategy on the first seven years of the data set – the in-sample data. You add filters, subtract rules, optimize parameters, etc. Once the strategy results are acceptable, whip out your “out of sample” data (the remaining 30% from your back pocket) and validate your findings.
If the strategy fails to produce similar results on the out of sample data, then you can be almost certain you have curve-fit to the first seven years of your data set.
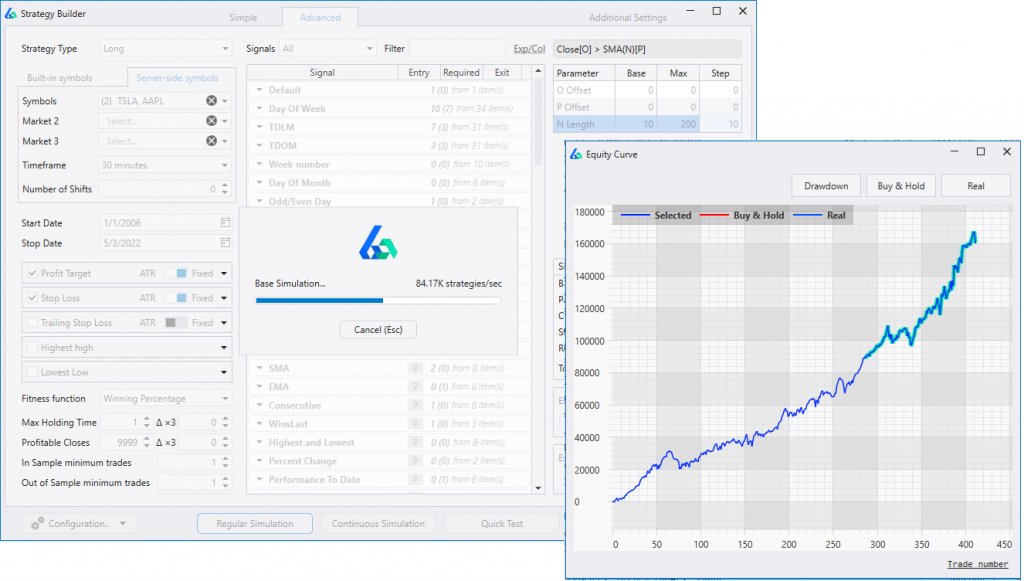
Below is a chart of an example strategy built using Build Alpha that highlights the out of sample period.
You like to see similar growth (and performance metrics) in both the in-sample and out-of-sample periods as sharp differences are often a red flag the hypothetical trading record was misleading.
On the other hand, successful OOS results are not necessarily indicative of future results and still involve financial risk but are a great first step to avoid overoptimization.
To read more about Out of Sample testing check out these blogs:
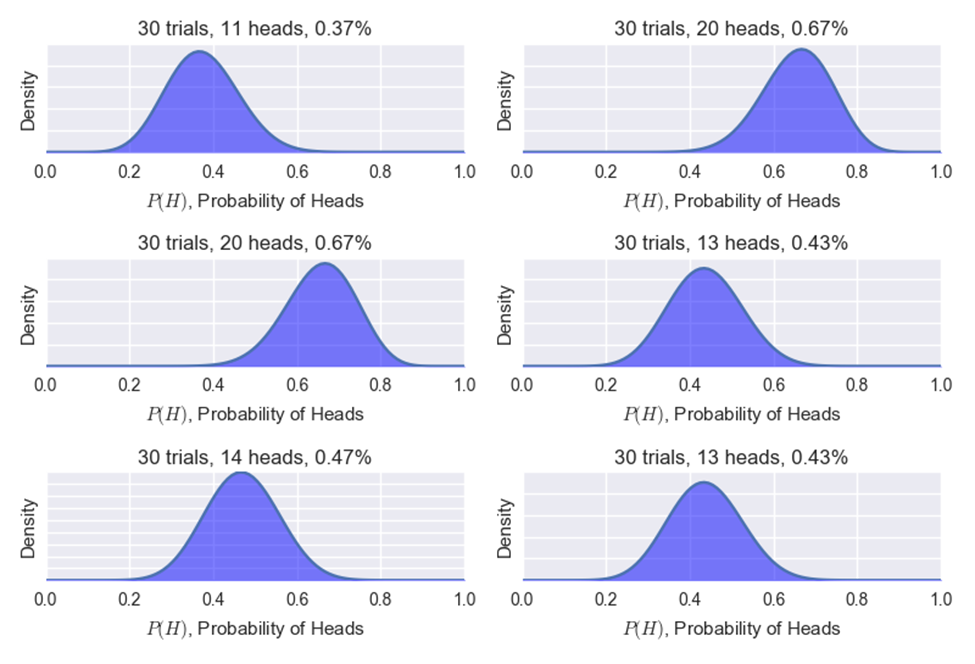
The second example of how we can reduce overfitting and hopefully our financial risk is to make sure your strategy has enough trades. If you flip a coin 10 times and it lands on heads seven times you cannot be certain you do or do not have a rigged coin.
However, if you flip a coin 10,000 times and it lands on heads 7,000 times then you can have high confidence it is a rigged coin.
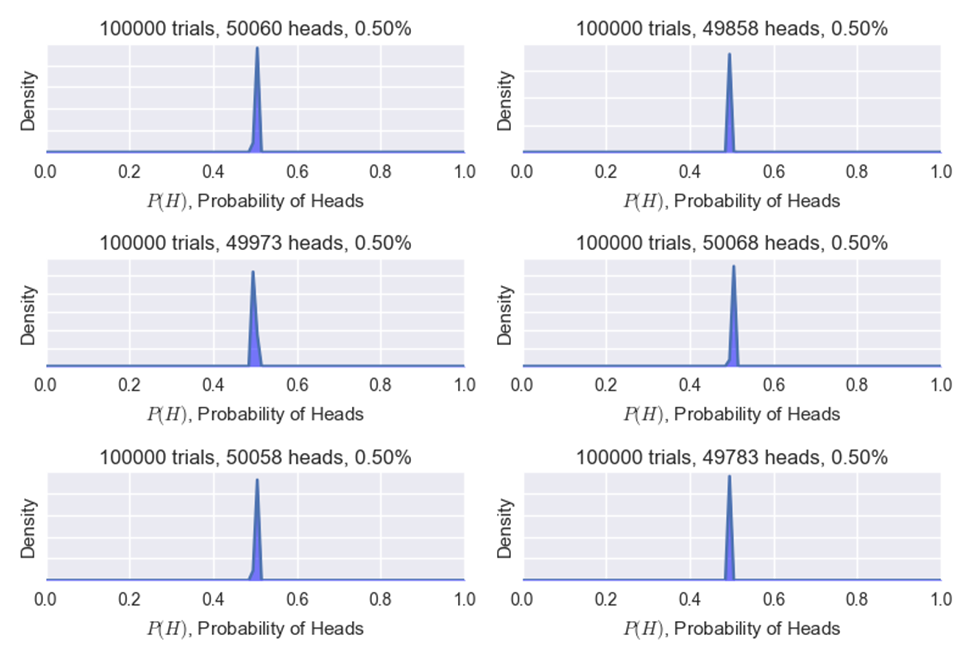
Below is a photo of only 30 coin flips and below that is a photo of six different trials of 100,000 coin flips. You can see after a large number of flips things tend to converge toward the true expectation or their expected value. This is known as the Law of Large Numbers.
Trading Example
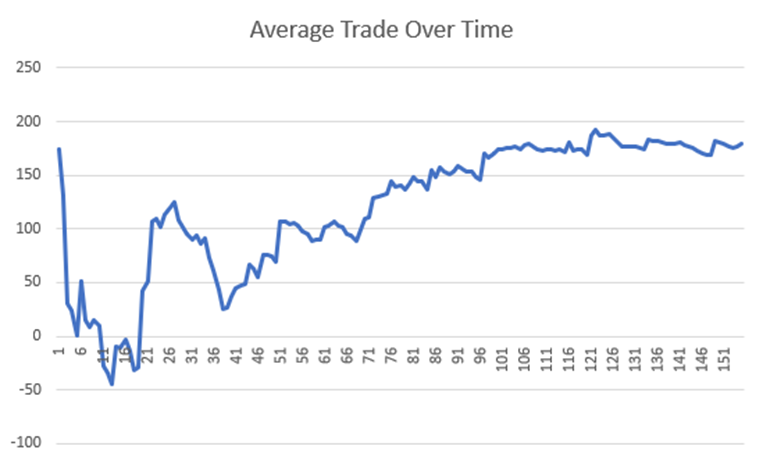
Let’s take this particular trading program below; it has a remarkably smooth cumulative profit graph and averaged $170 in profit per trade.
However, if we track this trading strategy’s average trade over time, we can see that in the beginning, when our trust in the trading system is lowest, it is a bumpy ride and far from the $170 per trade average. It takes about 100 trades for the average trade to converge to the actual results or average we expect!
Most traders cannot stomach this short-term “randomness” and abandon ship. Traders that fall prey to strategy hopping never achieve profits and sadly never find out why. They never escape this short-term randomness.
My mentor explained this short-term randomness, long-term obviousness concept to me and a lightbulb clicked.
Escaping Randomness was the perfect title of my Chat with Traders interview where I discuss how to overcome trading randomness and why algorithmic trading can help traders think about markets and risk-taking in a more productive way. If you haven’t already, please check out Aaron’s wonderful work here: Escaping Randomness with David Bergstrom
3. Validate Across Other Markets
Test your trading system across other markets. If a particular trading program only works on one market, then it has a higher chance of being overfit than if a strategy performs profitably on a handful of markets.
I am not saying that a trading strategy that only works on one market is curve-fit – as there are many nuances, different players, and idiosyncrasies that exist within each market.
However, if a trading strategy performs across markets, then in such cases you can certainly have higher confidence that it less likely curve-fit than a strategy that only performs well on one data set.
A sign of robustness is the ability to generalize to other data and withstand losses or is at least generally prepared for changes in the data.
Testing across similar markets is an easy way of quickly getting a sample of how well a strategy generalizes to new data sets.
Think of the cat picture above. If we provide new data is this algorithm going to draw a dog? It is most likely not the next series of points. Testing on a new data set and not finding other animals would indicate that the cat was probably random.
Other methods to catch Curve Fitted Strategies before live trading
I cover most of these in the aforementioned Robust Trading Strategy Guide but here is a popular list for those eager traders looking for more than the three simplest material points to combat curve fitting risk.
These robustness checks identify curve fitting and overoptimization before the market does:
Vs Shifted
shift the start and stop time of each bar slightly. Re-trade the strategy on the shifted data sets. For example, hourly bars from 11:03 to 12:03 instead of 11:00 to 12:00.
Vs Noise
add and subtract random noise amounts to the market data. Re-trade the strategy on the noise adjusted time series
Vs Random
data mine for the best possible random strategy. Your strategy should beat this random benchmark if it contains true market edge
Monte Carlo Analysis
reshuffle and reorder the hypothetical trading results to see various paths the strategy could have taken. More on Monte Carlo Simulation here.
Variance Testing
resample from trade distribution only keeping strategies that have a performance metric some percent lower than the original backtest
Parameter Sensitivity Testing
trading systems that fail to show positive performance as parameters change are often curve fitted. For example, a moving average of 12 works but parameters of 11 and 13 result in substantial trading losses or losses similar to a random strategy.
Delayed Testing
trading strategies that cannot perform similarly with slightly delayed entries or exits are potential substantial risk candidates
Liquidity Testing
trading strategies that are capacity constrained and cannot handle large amounts of capital are also potentially over fit models that will fail in live market trades
How can I reduce the risk of Curve Fit Strategies with Build Alpha
Build Alpha is professional algorithmic trading software that generates, tests and codes trading algorithms with no coding necessary. It is truly a no code algo trading software rich with features.
However, a large part of my research and testing over the past decade-plus of professional trading experience and software development has helped me develop and integrate these robustness tests into one piece of software – that is Build Alpha’s strength.
Build Alpha has all of the above listed tests available at the click of a button for use on any trading system it generates.
In plain English, there are many inherent limitations, and no amount of stress testing can completely account for curve fitting risk; however, as traders, all we can do is attempt to lower the probabilities that we have fit the data. Powerful software like Build Alpha exists to help traders easily test and validate trade ideas prior to exposing them to the market.
Many factors related, but avoiding overly optimistic hypothetical performance results, strategies with frequently sharp differences between testing periods, and highly sensitive parameter settings are good rules of thumb. However, it is important to use the robustness tests as much as possible as “eye-balling” has never been a solid approach to the markets.
Build Alpha comes complete with the litany of Robustness tests mentioned in this article. You can even import your own custom strategy to test inside Build Alpha.
How to avoid curve fitting in forex trading?
I get asked specifically about forex strategies and overfitting quite a bit. There are a few reasons I believe this to be a larger problem with forex trading than other asset classes.
First, forex has no central exchange, so fills are subject to the broker and essentially a function of his desires. Your historical simulated prices, backtest fills, and what happens in live can vary quite a bit.
Second, there are many forex scammers (I mean vendors) peddling overfit trading programs. The hypothetical performance results almost always differ from the actual results subsequently achieved in real markets. You can usually spot these guys by the too perfect equity curves and no knowledge of robustness testing.
This experience is not unique to forex markets but is certainly most prevalent here. There are other inherent limitations with buying trading systems, but this is not the place to discuss. It is best to build and test your own, so all risks are fully accounted for!
Curve Fit Key Takeaways
Past performance is not indicative of future results!
Curve fitting is a “too perfect” backtest that fails in actual trading
Curve fitting is the bane of most algo traders. Adversely affect trading results
Out of sample data is a first line of defense as it acts as unseen data
A large sample size of trades helps reduce the chances of finding something lucky
Validating across additional markets is a strong sign of robustness
Algo traders constantly battle the market’s complexity with their own complexity often leading to curve fit or overfit strategies which cause substantial risk to actual trading results.
Overfit trading strategies are frail, too good to be true strategies that fail when the market changes or a particular trading program is exposed to new market data or market conditions.
Over optimizing parameters or memorizing material points of the historical time series are the common culprits of failed accounts. Is it avoidable?
Traders can use robustness tests and methods on trading systems to help reduce the chances of overfitting such as:
out of sample testing
ensuring a large enough trade count
testing their trading strategy on various different markets
These tests do not guarantee trading systems are not a fitted curve but function to help reduce the risk of curve fitting in the market. Build Alpha aims to make this identification and testing easy and with no coding necessary.
Thanks for reading,
Dave
Author
David Bergstrom – the guy behind Build Alpha. I have spent a decade-plus in the professional trading world working as a market maker and quantitative strategy developer at a high frequency trading firm with a Chicago Mercantile Exchange (CME) seat, consulting for Hedge Funds, Commodity Trading Advisors (CTAs), Family Offices and Registered Investment Advisors (RIAs). I am a self-taught programmer utilizing C++, C# and python with a statistics background specializing in data science, machine learning and trading strategy development. I have been featured on Chatwithtraders.com, Bettersystemtrader.com, Desiretotrade.com, Quantocracy, Traderlife.com, Seeitmarket.com, Benzinga, TradeStation, NinjaTrader and more. Most of my experience has led me to a series of repeatable processes to find, create, test and implement algorithmic trading ideas in a robust manner. Build Alpha is the culmination of this process from start to finish. Please reach out to me directly at any time.
Python Tips for Algorithmic Trading [Reading Files, The Command Line]
Python Tips for Automated Trading
Python is the fastest growing and most popular programming language. This has drawn many quantitative traders, developers, and analysts to the easy-to-use and simple to understand scripting language. This post will cover a few python tips including reading text files, formatting dates and more essentials for automated trading.
Python has many popular finance and trading-based libraries for those that are interested in beginning their algo trading journey with python. The most popular trading library is probably talib which is a technical analysis library that has all the functions, indicators and math transforms an algo trader would need to start. Here is the talib documentation, if curious.
Reminder Build Alpha provides an easy way to get into automated trading without any programming. It does offer the ability to add custom signals via python for those of you that eventually want to learn or incorporate python into your process.
Is Python Good for algo trading
Python is an excellent choice for those traders that want to code themselves. The ease of learning, writing and understanding python code skyrockets it up the potential programming language list. Additionally, there are many good algo trading libraries that one can use freely. This saves the algo trader from having to recreate the wheel.
It is important to note that python does have its limitations when it comes to very large data sets or the need for speed. Other programming languages, like C++, are better suited for high frequency trading. I compare Python and C++ in my Algo Trading Guide.
The most popular python library, pandas, was created by a quantitative trading firm. AQR Capital Management began the project in 2008 before open sourcing it in 2009.
Why Python?
Python’s beauty is its simplicity. Python’s simplicity is its beauty. Unlike other programming languages, python does not use brackets to identify code blocks or semi-colons to end statements. Python simply relies on neatly written and indented code for the interpreter to grasp.
On top of the ease of use, Python’s mainstream popularity is due to the growing number of public libraries with python solutions. This gives many python coders an easy introduction to solving a problem or often a solution. For instance, no need to re-code a technical indicator if someone has already added it to the aforementioned talib library. You can simply access or use the code from talib.
Python Read in Financial Data
The first tutorial goes over how to read in a text file, format dates, and create new columns inside a pandas data frame. A data frame is a structure that stores your data in a convenient “table” for easy access. There are a few parts, but I will break down the code below.
The first thing we will do is import pandas library and call the built-in read_csv function. The read_csv function’s first input is the name of the file you desire to read in and store in your pandas’ data frame. The delimiter option allows you to specify the character that separates your text fields within your file.
import pandas as pd
df = pd.read_csv("ES.txt",delimiter=',')
Just like that, we have read a text file into a pandas’ data frame that we can now work with.
However, if we were to plot our data frame (closing prices) now the x-axis would simply be the number of bars as we did not specify an index column. In trading and time series analysis it is often nice to have dates as your x-axis.
Python Working with Dates
In the next few lines of code, I import a built-in python library that can read string dates (“12/30/2007”) and convert them into Python “DateTime” objects. To simplify this… we convert dates into Python dates.
I accomplish this by setting the built-in pandas index column to a list of newly Python formatted dates. I essentially loop through each string date, convert it, and add it to our data frame’s index. I then delete the original string Dates column.
from dateutil import parser
df.index = [parser.parse(d) for d in df['Date']]
del df['Date']
Now we can plot our closing prices and our x-axis will be dates.
In the code below I create a new column called “Range”. Notice how Python understands I want to do the calculation on all the highs and lows inside our data frame without me specifying so!
df['Range'] = df['High'] - df['Low']
Finally, the line below plots our Close and Range in two separate plots. This is from a previous tutorial video.
df[['Close','Range']].plot(subplots=True)
Python using the command line
The second part of this tutorial is to make our lives easier. Let’s say that we wanted to run that last program on a bunch of different stocks whenever we wanted. It would be quite annoying to open up the file or notebook and change the filename in our read_csv function every time.
Instead, we can create a filename variable and put the filename variable inside the read_csv function. Ideally, this filename variable could be dynamically set with user input from the command line.
This code is tricky and has a few moving parts. Below is the code and then I will explain what we did.
symbol = 'ES'
import sys,getopt
myopts,args = getopt.getopt(sys.argv[1:],"s")
for o,a in myopts:
if o == '-s':
symbol = str(a).upper()
filename = "%s.csv" % symbol
df = pd.read_csv(filename,delimiter=',')
First, we created a symbol variable that will accept our user input. Second, we imported some built-in libraries and called the getopt function to read user input. We also specified that our desired input would be preceded by the “s” option.
We then wrote a simple for loop to read through all the command line inputs (which in this example is only one, but this template will allow you to create multiple command line input options). We then said, “if the command line option is ‘s’ then set the symbol variable to whatever follows it”. We also morphed “whatever follows it” into an upper case, string variable to avoid case-sensitive user input.
We then set our filename variable and proceeded to read our text file into our data frame (df) as before.
This is complicated, but a major time saver. Please review this video Python – Command Line Basics as the extra 3 minutes might save you hours of our life by utilizing tricks like this!
Python for Algo Trading with Build Alpha
Build Alpha is algorithmic trading software that creates thousands of systematic trading strategies with the click of the button. Everything is point and click and made for traders without any programming capabilities.
However, I recently added the ability to add custom entry or exit signals via python for those that want to get even more creative or have existing indicators they would want to throw into the Build Alpha engine.
This is the fastest road to algo trading with the most flexibility. It allows you to test without wasting time coding up every single idea, but still permitting you to add unique ideas via python whenever inspiration strikes. To see how you can add custom signals via python to Build Alpha please head here: buildalpha.com/python
This is complicated, but a major time saver. Please review the video as the extra 3 minutes might save you hours of our life by utilizing tricks like this!
Remember for those of you who don’t want to learn programming you can use research tools like Build Alpha to save even more time.
For this Free Friday edition I want to talk about market regimes or market filters. I have a very simple intermarket filter or regime monitor to share.
The idea with market regimes or filters is to identify a condition or set of conditions that alters the market’s characteristics or risk profile. Ideally, you could find a bull and bear regime that would enable you to go long when in the bull regime and get into cash or go short when in the bear regime.
The simple regime filter I want to share was found using Build Alpha’s Intermarket signals. It only uses one rule and creates a clear bullish and bearish regime.
The rule says that if the Close of Emini S&P500 divided by the Close of the US 10 Yr Notes is less than or equal to the 10 days simple moving average of the Emini S&P500 divided by the 10 days simple moving average of the US 10 Yr Notes then we are in the bull regime.
Here it is in pseudo-code assuming eMini S&p500 is market 1 and US 10 Yr Note is market 2.
Let’s verify with some numbers that we have a discernible difference in market activity before I start flashing some charts at you.
Here are the S&P500’s descriptive statistics when in the bull regime:
Average Daily Return: 1.20
Std Dev Daily Return: 17.49
Annualized Information Rate:
1.09
Here are the S&P500’s descriptive statistics when in the bear regime:
Average Daily Return: -0.34
Std Dev Daily Return: 12.11
Annualized Information Rate:
-0.44
This would definitely qualify as something of interest. Let’s take a look at the equity curve going long when ES, the eMini S&P500 futures, enter into the bull regime.
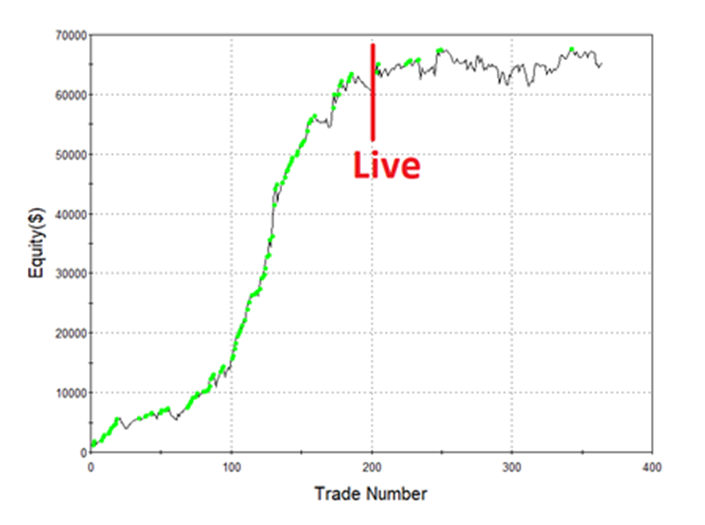
It actually performed quite well with no other rules or adjustments only trading 1 contract since early 2002. It even looks to have started to go parabolic in the out of sample data (last 30% highlighted).
Build Alpha now offers another check for validity -> The ability to test strategy rules across other markets. This is very important when determining how well a rule generalizes to new (and different) data. The user can select whatever markets to compare against, but in the example below I chose the other US equity index futures contracts. You can see Nasdaq futures in gold, Russell Futures in green, and Dow Jones futures in red.
Now back to our Free Friday regime filter… Wouldn’t it be cool if the US 10 Yr Note performed well while Emini S&P500 was in the bear regime? That way instead of divesting from the S&P500 and going into cash we could invest in US 10 Yr Notes until our bull regime returned.
Well, guess what… the US 10 Yr Note Futures do perform better in the bear regime we’ve identified.
The best part is… Build Alpha now lets you test market regime switching strategies.
That is, invest in one market when the regime is good and invest in another market when the regime changes. This ability smoothed our overall equity curve and increased the profit by about 50%! Below is an equity curve going long Emini S&P500 in the bull regime and going long US 10 Yr Note Futures when the regime turns bearish.
Some major new additions coming to Build Alpha and I’ll be announcing them soon. As always thanks for taking the time to read these.
Out of Sample Data – How the Human Can Add Value to the Automated Trading Process
First, I need to describe over-fitting or more commonly known as curve-fitting. Curve-fitting is creating a model that too “perfectly” fits your sample data and will not generalize well on new unseen data. In trading, this can be thought of as your model too closely fits the historical data and will surely fail/struggle to adapt to new live data.
Here are two visuals I found to help illustrate this idea of curve-fitting.
How can we avoid curve fitting?
The simplest and best way to avoid (or reduce our risk of) curve-fitting is to use “Out of Sample” data. We simply designate a portion of our historical data (say the last 30% of the test period) to act as our unseen or “Out-of-Sample” data.
We then go about our normal process designing/testing/optimizing rules for trading or investing using only the first 70% of the test period or the “In-Sample” data.
After finding a satisfactory trading method we pull out our Out of Sample data and test on the last 30% of our test period.
It is often said that if the model performs similarly in both the in and out of sample data then we can have increased confidence the model generalizes well enough to new data.
No need to bring up selection bias or data mining here, but I will certainly cover it in another post/video series.
How can the human add value to the automated trading process?
The intelligent reader will question why we chose 30% and why the last portion of the data (as opposed to the first 27% or last 15%)?
The trader can add value and increase a trading model’s success by controlling the
Date Ranges of entire test
Out of sample location
Percentage of out of sample data
I have always heard that good science is often mostly attributable to good experimental design. In the trader’s case, good science would be setting up a proper test by choosing an appropriate test period, out of sample location, and out of sample percent.
Trading Data Example
Let’s take a look at the S&P500 from 2004 to 2017. In the chart below I have designated the last 40% of the data to be our Out of Sample data.
This means we would create a trading model on the data from 2004 to roughly 2011 – the blue In Sample data. However, 2011 to present day (red Out of Sample) has been largely straight up.
If we build a long strategy that avoids most of 2008 via some rule or filter it may certainly do well in on our Out of Sample data simply because the underlying market went straight up!
You can see the importance of intelligently selecting your test period and out of sample period’s location and size.
What if we used the first 40% of the data as our Out of Sample data? This provides a few benefits. First, it allows us to build our trading model on the most recent data or the last 60% of the data set – in our case 2009 to 2017.
Many traders will argue that they prefer to build their models on the most recent data as it is most likely the most similar to the live data they will soon experience. They then obviously test Out of Sample but just use older data and in our case 2004 to 2008 or the first 40%.
Now how did I know 40%? I simply looked at the chart and selected a percentage that would capture the financial crisis. My thought process is that if we train a model from 2009 to 2017 and then test it on 2004 to 2008 and it performs similarly in both periods then we surely have uncovered some persistent edge that generalizes over two unique sets of data. The two unique sets being our In-Sample (2009 to 2017) and our Out-of-Sample (2004 to 2008).
Selecting a proper location and percentage is mission critical. You want to design your test to be as difficult as possible to pass – try to break your system in the testing process. If you do not, then the market will surely break it once you start live trading!
Testing design and set up is undoubtedly where the human still adds value to the automated trading process. Build Alpha allows users to leverage computational power in system design, validation, and testing; however, the test set-up in BA is still an area where a smarter, more thoughtful trader can capture an edge over his competitors and add robustness to the output.
Bad Examples of OOS Data
Below I have some photos of some terrible experiment design to help drive the point home. Both present fairly simple out of sample tests to “pass”. Passing OOS testing is not the goal. Creating robust strategies is. This requires difficult OOS tests to pass (not what is pictured below). Please watch the video above for an explanation.
Takeaways
The main takeaway is that the human can still add value to the automated trading process by proper test/experiment design. That is why BuildAlphasoftware allows the trader/money manager to adjust everything (or nothing) from
Test Period
Out of Sample percent
Out of Sample location
In-Sample Minimum number of trades
Out of Sample minimum number of trades
I hope this was helpful – catch you in the next one,
In this post I will go over a few different ways to manipulate price data to create visuals to aid in the investing and trading research process. I have attached a ten minute YouTube video that has explanations, etc. However, this post also attempts to briefly walk you through the Python code.
First, we will use some Python code to download some free data from the Yahoo Finance API. The code below creates a function called “get_data” that downloads and adjusts price data for a specified symbol over a specified period of time. I then download and store $SPY and $VIX data into a pandas dataframe.
import pandas as pd import matplotlib.pyplot as plt from datetime import datetime from pandas_datareader import data import seaborn as sns
This next piece of code is two ways to accomplish the same thing – a graph of both SPY and VIX. Both will create the desired plots, but in later posts we will build on why it is important to know how to plot the same graph in two different ways.
The first method is simple and straight forward. The second method creates a “figure” and “axis”. We then use plt.subplot to specify how many rows, columns, and which chart we are working with. For example, ax = plt.subplot(212) means we want to set our axis to our display that has 2 rows, 1 column, and we want to work with our 2nd graph. plt.subplot(743) would be 7 rows, 4 columns, and work with the 3rd graph (of 28). You can also use commas to specify like this plt.subplot(7,4,3).
Anyways, here is the output.
The next task is to mark these graphs whenever some significant event happens. In this example, I show code that marks each time SPY falls 10 points or more below its 20 period simple moving average. I then plot SPY and mark each occurrence with a red diamond. I also added a line of code that prints a title, “Buying Opportunities?”, on our chart.
df['MovAvg'] = Ticker1['Close'].rolling(20).mean() markers = [idx for idx,close in enumerate(df['spy']) if df['MovAvg'][idx] - close >= 10] plt.suptitle("Buying Opportunities?") plt.plot(df['spy'],marker='D',markerfacecolor='r',markevery=markers)
This code creates a python list named markers. In this list we loop through our SPY data and if our condition is true (price is 10 or more points below the moving average) we store the bar number in our markers list. In the plot line we specify the shape of our marker as a diamond using ‘D’, give it the color red using ‘r’, and mark each point in our markers list using the markevery option. The output of this piece of the code is below.
Next, and simply, I show some code on how to shade an area of the chart. This may be important if you are trying to specify different market regimes and want to visualize when one started or ended. In this example I use the financial crisis and arbitrarily defined it by the dates October 2007 to March 2009. The code below is extremely simple and we only introduce the axvspan function. It takes a start and stopping point of where shading should exist. The code and output are below.
Personally I do not like the shading of graphs, but prefer the changing of the lines colors. There are a few ways to do this, but this is the simplest work around for this post. I create two empty lists for our x and y values named marked_dates and marked_prices. These will contain the points we want to plot with an alternate color. I then loop through the SPY data and say if date is within our financial crisis window then add the date to our x list and add the price to our y list. I do this with the code below.
marked_dates = [] marked_prices = []
for date,close in zip(df.index,df['spy']):
if date >= datetime(2007,10,1) and date <= datetime(2009,3,9):marked_dates.append(date) marked_prices.append(close)
I then plot our original price series and then also plot our new x’s and y’s to overlap our original series. The new x’s and y’s are colored red whereas our original price series is plotted with default blue. The code and output is below.
That’s it for this post, but I hope this info helps you in visualizing your data. Please let me know if you enjoy these Python tutorial type posts and I will keep doing them – I know there is a huge interest in Python due to its simplicity.
Also, I understand there may be simpler or more “pythonic” ways to accomplish some of these things. I am often writing this code with intentions of simplifying the code for mass understanding, unaware of the better ways, or attempting to build on these blocks in later posts.
Cheers,
Dave
It has been brought to my attention that Yahoo Finance has changed their API and this code will no longer work. However, we can simply change the get_data function to the code below to call from the Google Finance API
def get_data(symbol,start_date,end_date):
dat = data.DataReader(symbol,"google",start_date,end_date)
dat = dat.dropna()
return dat
Google adjusts their data so we do not have to. So I removed those lines. I also swapped out ‘yahoo’ for ‘google’ in the DataReader function parameters. Google’s data is also not as clean so I added a line to drop NaN values. That’s it. Simple adjustment to change data sources.
Thanks for reading, Dave
Free Friday Update March 2017
Happy Friday!
For this Free Friday edition, I will just share an update of the Free Friday strategies performance.
One month is not indicative of anything and these are just meant for educational purposes (strategies may or may not have gone through the entire rigor of the robustness/validation techniques described on this site and offered within the software).
A lot of these strategies were built to demonstrate a specific Build Alpha feature and are for demonstrations purposes… always fun to track performance, however.
I post the strategies on Twitter and you can find them here: @dburgh or here: www.buildalpha.com/blog
All in all, not a bad month. A few things to consider… 1. One month is by no means telling, but it is sure nice to see profits. 2. As mentioned not all these strategies went through the full spectrum of validation techniques. 3. Strategy #6 only has 1 rule so it is much more common for its entry condition to be satisfied; hence the larger number of trades each month. 4. All of these results based on 1 futures contract traded or 1000 ETF shares traded – very simple.
Please note I only include trades that are “live” or occur after I’ve publicly posted the strategy.
Also, the Free Friday strategies were by no means designed as a portfolio. Having a strategy, like FF6, trading frequently and others hardly trading at all would be ill-advised in most cases. These are simply for demonstration purposes and fun to track.
Happy Friday. The trader in me could not risk doing Free Friday #13 so I decided to release 2 strategies this week (14 and 14a).
The first strategy shorts $GDX, the Gold Miners ETF, and the second strategy goes long $GLD, the Gold ETF.
The strategy above is the GDX short strategy. The left chart is from Build Alpha (which now highlights out of sample trades – new feature) and the right chart is from TradeStation. Please note Build Alpha tested with only 100 shares per trade whereas the TradeStation charts in this post show results for 1,000 shares per trade. Below are the strategy results pulled from TradeStation.
Notice this GDX strategy takes Intermarket signals. One from SPY and one from GLD. The GLD signal is translated as the square root of this bar’s high * low is greater than the square root of the previous bar’s high * the previous bar’s low.
The second strategy is obviously the long GLD strategy. The chart below to the left is generated with Build Alpha using 100 shares per trade. The chart on the right replicated the strategy in TradeStation using 1,000 shares per trade (my laziness).
Please note the highlighted, out of sample, the section is at the beginning. Many traders prefer to build/train their model on the most recent data and use old data as the out of sample test data. Build Alpha now allows the trader this option through the updated settings menu (pictured later).
Please note the GLD strategy also uses Intermarket signals – in this case using XLU, the utilities ETF, for a pair of signals. Below I’ve attached a photo of the new settings menu to highlight how simple it is to change the out of sample period to the beginning or back to the end of the data.
Wrapping this up so you can get on with your weekend, I just want to show the combined chart of this long/short Gold strategy. Going Long GLD and short GDX when conditions are met. Obviously, and based on this post’s title, Build Alpha also permits multi-market portfolios now.
Happy Friday. This week’s Free Friday strategy is for $XLP or the ETF that tracks US Consumer Staples. However, it was designed taking input from two other popular ETFs.
Here is the equity curve and backtest results. The left is a graph created by TradeStation and the right is a graph showing our backtest results (blue) and XLP buy and hold (grey). The chart on the right, created by Build Alpha, is plotted by date whereas the TradeStation chart is plotted by trade number – both software have the ability to plot both x-axis styles.
This strategy uses only 3 rules for entry
XLP’s 2 Period RSI must be lower than it was 1 bar ago
XLU – Utility ETF – must close below its midpoint
XLE – Energy ETF – must be below its 3 period Simple Moving Average
The exits for this strategy are two-fold
Maximum hold of 4 days
Exit on the first profitable close
Below are the trade statistics for this Free Friday Strategy.
I know want to introduce another, and new, Build Alpha test to help validate trading strategies. I first mentioned this test here: Better System Trader Podcast. The Noise Test is a popular test that allows the user to randomly add AND subtract noise from the historical price data. The user can specify how much of the data he/she wants to adjust and by how much he/she wants to adjust the data.
For example, the user can change 50% of the data by 25% of the average true range. This means we would adjust the data by either adding or subtracting up to 25% of the average true range to any of the opens, highs, lows or closes until we’ve adjusted 50% of the data.
We now have a “new” data set that contains a different amount of noise. Build Alpha will continue to create 100 new data sets all with differing noise characteristics. Finally, we will re-trade our strategy on these 100 new data sets to see how well it performs had the noise been different.
The idea is… does your strategy fall off a cliff if some other amount of noise is introduced or subtracted to your underlying data set?
I will show results for two noise tests I ran on this Free Friday strategy.
My first configuration was to adjust all the opens, highs, lows and closes at the same rate (20%). Furthermore, I only wanted to add or subtract up to 20% of the average true range whenever making a change.
As you can see the strategy is not very “anti-fragile”. That is, changing the noise amount never produced better results than our backtest. This can be a major red flag. However, the strategy still maintained general profitability over the 100 tests. I was pleased enough to run a second test. This time more creative with the adjustments to the data.
Adding or subtracting up to 55% of the average true range to differing amounts of the opens, highs, lows, and closes produced the above graph. This Noise Test has me much less confident in the strategy. For instance, our original backtest is now a significant outperformer. This generally means that it was too reliant to the underlying data. However, it does maintain overall profitability across the tests so may contain some actual edge nonetheless.
If up to me, I would continue researching this strategy and others as this is not an overwhelming pass.
The Noise Test is just another robustness check that Build Alpha offers to give traders and money managers every tool possible.