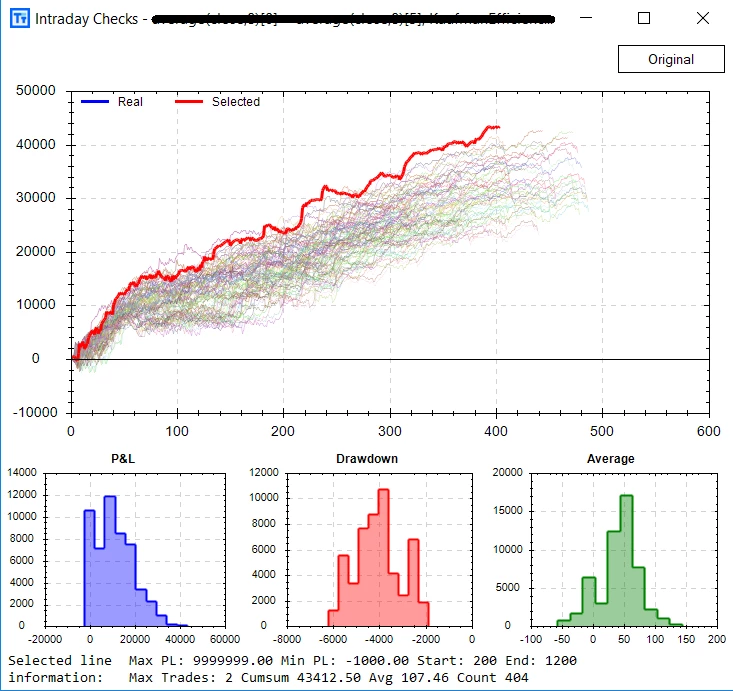
This new feature opens the door for what is possible in Build Alpha. Traders can leverage the power of python as well as BuildAlpha in extremely easy to use ways.
Moving Average Trading Strategy Python
Build Alpha’s python environment is a full python environment which means we can import external libraries. Let’s import the famous technical analysis library, talib, to create a moving average trading strategy with python.
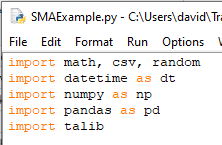
Create a new indicator and add `import talib` at the top of the python file.

Install Python Library for Technical Analysis Indicators
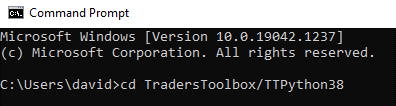
If you do not have talib installed, then open a command terminal and navigate to your python directory. You can type ‘cmd’ into the start menu of most Windows devices. If you used the Build Alpha installer then talib is included. However, you can navigate to your python directory like this:
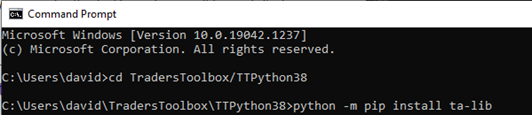
Then install talib using the following prompt. Notice the hyphen in ta-lib.
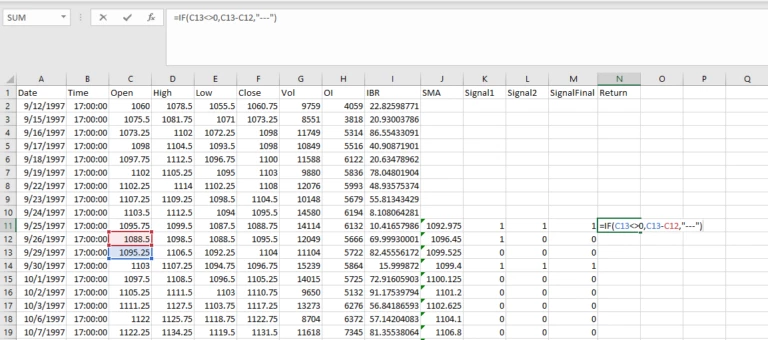
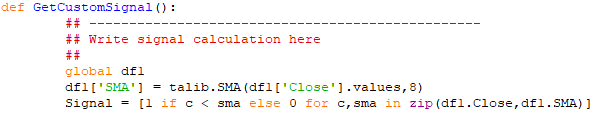
Next let’s calculate an 8-period moving average and create a signal that is true when the close price is below the 8-period SMA. Both code and screenshot are below.
def GetCustomSignal():
##-----------------------------------------
## Write signal calculation here
##
global df1
df1['SMA'] = talib.SMA(df1['Close'].values,8)
Signal = [1 if c < sma else 0 for c,sma in zip(df1['Close'],df1['SMA'])]
`
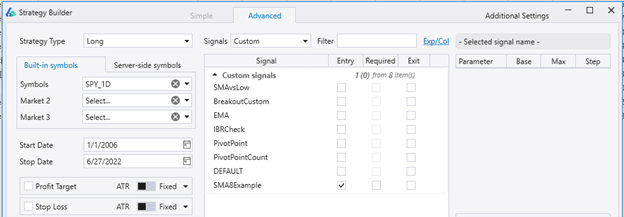
Then you can access this signal in the Custom list of the main Strategy Builder screen.
You can then combine it with any other Build Alpha signal or feature as if it were a built-in signal. This one of course is a built-in signal but made for a simple talib example.
Algorithmic Trading Python
Python is the fastest growing and most versatile programming language making it extremely attractive for quantitative traders and developers. Many algo traders prefer python due to its easy-to-read code and simple syntax. Python does not require code block brackets or semi-colons to end statements, but still is object oriented providing a great mix of ease and flexibility.
Python for algorithmic trading is growing every day with new libraries and popular libraries being updated. TALIB is the most popular library, but many more advanced libraries continue to pop up. Algo trading with python has never been easier.
However, connecting to exchanges, handling live price data, and coming up with trading ideas can be a daunting task. The best part about coding is coming up with new signals. Build Alpha takes care of the heavy lifting enabling python traders to simply do the fun part: signal creation.
Summary
Build Alpha now supports the ability to import custom signals via python. This is additional functionality for programmers that want to leverage the speed and ease of Build Alpha. Reminder that this is extra and NO programming is needed to use Build Alpha’s built-in signals or drag and drop custom signal builder.
It has been one heck of a year for Build Alpha’s development and there is still so much to do in 2018! Thanks for all those that support the software; I am looking forward to next year.
Author
David Bergstrom – the guy behind Build Alpha. I have spent a decade-plus in the professional trading world working as a market maker and quantitative strategy developer at a high frequency trading firm with a Chicago Mercantile Exchange (CME) seat, consulting for Hedge Funds, Commodity Trading Advisors (CTAs), Family Offices and Registered Investment Advisors (RIAs). I am a self-taught programmer utilizing C++, C# and python with a statistics background specializing in data science, machine learning and trading strategy development. I have been featured on Chatwithtraders.com, Bettersystemtrader.com, Desiretotrade.com, Quantocracy, Traderlife.com, Seeitmarket.com, Benzinga, TradeStation, NinjaTrader and more. Most of my experience has led me to a series of repeatable processes to find, create, test and implement algorithmic trading ideas in a robust manner. Build Alpha is the culmination of this process from start to finish. Please reach out to me directly at any time.
























































![A Strategy For Each Day of the Week [Seriously?]](https://www.buildalpha.com/wp-content/w3-webp/uploads/2018/04/DayOfWeek.pngw3.webp)










![Using Python in Build Alpha [Creating Custom Signals]](https://www.buildalpha.com/wp-content/w3-webp/uploads/2017/12/CustomRule.pngw3.webp)




![Mean Variance Optimization [Portfolio Construction]](https://www.buildalpha.com/wp-content/w3-webp/uploads/2017/05/MV_1.pngw3.webp)